
Cos'è JPA?
JPA è un framework e una specifica Java che sta per Java Persistence API.
Come si evince dal nome, offre delle API per aiutare gli sviluppatori nelle operazioni di persistenza dei dati su un
database relazionale. In particolare:
- fornisce una mappatura tra classi Java e tabelle del database
- fornisce un linguaggio per effettuare query SQL, chiamato JPQL (Java Persistence Query Language), che è indipendente dalla DBMS utilizzato
- fornisce varie API per la gestione e manipolazioni degli oggetti Java che mappano le tabelle del database.
Queste tre caratteristiche possono essere riassunte con una sola frase: JPA è un framework che utilizza la tecnica dell'ORM (Object-Relational Mapping).
Abbiamo anche detto che fornisce della API, quindi delle interfacce: ci sono allora vari provider che implementano questa specifica; i più famosi sono Hibernate ed EclipseLink.
In questo primo articolo vedremo come mappare su JPA le relazioni OneToMany, OneToOne, ManyToMany.
Prerequisiti
- Aver installato una jdk (useremo la versione 8 ma va bene anche una successiva).
- Aver installato maven (https://maven.apache.org/install.html).
Primo passo: importare le seguenti dipendenze
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.4.24.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<version>1.0.2.Final</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Da notare che useremo la versione 2.1 di JPA, utilizzeremo Hibernate come provider JPA e sfrutteremo H2 come database in-memory.
Secondo passo: creimo la entity UserEntity (relazione one to many, one to one e many to many)
Nel DB avremo queste tabelle:
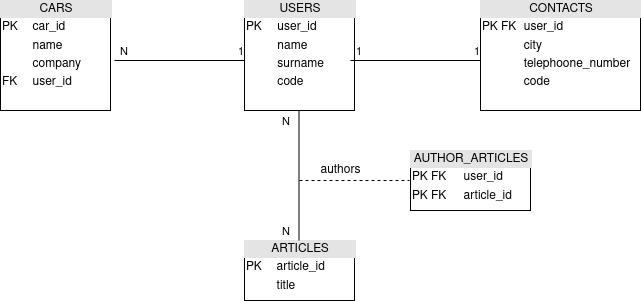
Quindi la tabella USERS è in relazione 1:1 con CONTACTS, è in relazione 1:N con la tabella CARS e infine è in relazione N:N con la tabella ARTICLES, quindi è presenta una tabella di associazione AUTHOR_ARTICLES.
Creiamo un sottopackage entities e lì scriviamo le classi Java che mappano queste tabelle. Creeremo delle relazioni bi-direzionali, ossia le associazioni saranno mappate con JPA sia dalle classi padre che da quelle figlie.
Inoltre ogni entity implementarà una interfaccia creata da noi, JpaEntity: questo può portare dei vantaggi per sviluppi che faremo in futuro:
public interface JpaEntity extends Serializable {
}
UserEntity:
@Entity
@Table(name = "USERS")
public class UserEntity implements JpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long id;
private String name;
private String surname;
private String code;
@OneToMany(mappedBy = "userEntity")
private Set<CarEntity> cars;
@OneToOne(mappedBy = "userEntity", cascade = CascadeType.ALL, orphanRemoval = true)
@PrimaryKeyJoinColumn
private ContactEntity contactEntity;
@ManyToMany(mappedBy = "authors")
private Set<ArticleEntity> articles;
public void addCar(CarEntity carEntity) {
carEntity.setUserEntity(this);
if(this.cars == null) {
this.cars = new HashSet<>();
}
this.cars.add(carEntity);
}
public void removeCar(CarEntity carEntity) {
this.cars.remove(carEntity);
carEntity.setUserEntity(null);
}
public void addArticle(ArticleEntity articleEntity) {
if(articleEntity.getAuthors() == null) {
articleEntity.setAuthors(new HashSet<>());
}
if(this.articles == null) {
this.articles = new HashSet<>();
}
articleEntity.getAuthors().add(this);
this.articles.add(articleEntity);
}
public void removeArticle(ArticleEntity articleEntity) {
this.articles.remove(articleEntity);
articleEntity.getAuthors().remove(this);
}
//getters, setters, equals, hashcode
}
Analizziamo il codice:
- Con @Entity stiamo indicando a JPA che questa classe Java mappa una tabella del database.
- Con @Table(name = "USERS") indichiamo a JPA che il nome della tabella mappata è USERS. Senza questa annotation, cercherebbe
una tabella con lo stesso nome della classe Java.
3) Con @Id indichiamo che il campo annotato è una primary key.
4) Con @GeneratedValue(strategy = GenerationType.IDENTITY) indichiamo che l'id è una IDENTITY (cioè è un campo che viene auto-incrementato
dal DBMS).
5) Con @Column(name = "user_id"), indichiamo a JPA che questo campo Java mappa la colonna user_id. Senza questa annotation, JPA
cercherebbe di mappare una colonna con lo stesso nome del campo Java.
6) Con @OneToMany(mappedBy = "userEntity") stiamo dicendo a JPA che questa tabella è in relazione 1:N con la classe CarEntity
che mappa la tabella CARS. Inoltre, con mappedBy indichiamo a JPA che CarEntity ha un attributo chiamato userEntity per mappare la relazione
inversa N:1.
7) Con @OneToOne(mappedBy = "userEntity", cascade = CascadeType.ALL, orphanRemoval = true) stiamo indicando a JPA che c'è una relazione 1:1
con la classe ContactEntity che mappa la tabella CONTACTS. Il discorso del mappedBy è uguale al punto 6. Inoltre, con cascade = CascadeType.ALL,
indichiamo che è attivo il cascade su tutte le operazioni di INSERT, UPDATE, DELETE (non è obbligatorio avere il cascade lato db). Infine, con
orphanRemoval = true indichiamo che se un figlio, ContactEntity, rimane "orfano" del padre, UserEntity, (ovvero ha foreign key null), deve
essere cancellato automaticamente.
8) Con @PrimaryKeyJoinColumn, indichiamo a JPA che la tabella CONTACTS ha come chiave primaria la stessa della tabella USERS.
9) Con @ManyToMany(mappedBy = "authors") indichiamo a JPA che c'è una relazione N:N con la classe ArticleEntity e che ArticleEntity ha una collezione
di UserEntity con nome authors.
Inoltre è buona norma aggiungere metodi add e remove come addCar e removeCar che oltre ad aggiugere/rimuovere una Car dalla lista, referenzia/de-referenzia anche nella classe figlio l'istanza del padre (carEntity.setUserEntity(this) e carEntity.setUserEntity(null)).
Un'altra buona norma è settare il nome delle tabelle in plurale (USERS) mentre quelli delle classi Java in singolare (User o UserEntity).
Ovviamente, nessuna di queste due indicazioni sono obbligatorie.
Terzo passo: creimo la entity CarEntity (relazione many to one)
@Entity
@Table(name = "CARS")
public class CarEntity implements JpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "car_id")
private Long id;
private String company;
private String name;
@ManyToOne
@JoinColumn(name = "user_id")
private UserEntity userEntity;
//getters, setters, equals, hashcode
}
Analizziamo il codice:
- Con @ManyToOne indichiamo a JPA che CarEntity è in relazione N:1 con UserEntity. Quindi il campo userEntity lato DB sarà una FK.
- Con @JoinColumn(name = "user_id") indichiamo a JPA qual è il nome della colonna che fa da FK. Siccome sia nella tabella CAR che nella tabella
USERS la colonna che fa da FK ha lo stesso nome, basta usare name = "user_id", altrimenti, se la tabella USERS avesse come nome della colonna PK "id", saremmo stati costretti a scrivere in questo modo @JoinColumn(name = "user_id", referencedColumnName = "id").
Quarto passo: creimo la entity ContactEntity (relazione one to one)
@Entity
@Table(name = "CONTACTS")
public class ContactEntity implements JpaEntity {
@Id
@Column(name = "user_id")
private Long id;
private String city;
@Column(name = "telephone_number")
private String telephoneNumber;
@OneToOne
@JoinColumn(name = "user_id")
@MapsId
private UserEntity userEntity;
//getters, setters, equals, hashcode
}
Analizziamo il codice:
- Con @OneToOne e @JoinColumn(name = "user_id") stiamo dicendo a JPA che la colonna FK della relazione 1:1 è mappata lato tabella CONTACTS.
- Con @MapsId stiamo inoltre dicendo che la FK è anche PK della tabella CONTACTS.
Quinto passo: creimo la entity ArticleEntity (relazione many to many)
@Entity
@Table(name = "ARTICLES")
public class ArticleEntity implements JpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "article_id")
private Long id;
private String title;
@ManyToMany
@JoinTable(name = "AUTHOR_ARTICLES", joinColumns = {
@JoinColumn(name = "article_id")
}, inverseJoinColumns = @JoinColumn(name = "user_id"))
private Set<UserEntity> authors;
//getters, setters, equals, hashcode
}
Analizziamo il codice:
- Con @JoinTable(...) stiamo indicando a JPA il nome della tabella d'associazione (AUTHOR_ARTICLES) e quali sono le PK/FK che la compongono.
Notiamo che per le relazioni N:N, lato JPA non dobbiamo mappare la tabella di associazione con una classe Java.
E se volessimo aggiungere altri campi nella tabella d'associazione AUTHOR_ARTICLES? In questo caso non possiamo parlare più di una vera tabella di associazione, in quanto quest'ultima serve solo a memorizzare le associazioni tra più tabelle. Possiamo però scomporre una relazione many to many in due relazioni one to many con una terza tabella "concreta" (ossia AUTHOR_ARTICLES), in questo modo:
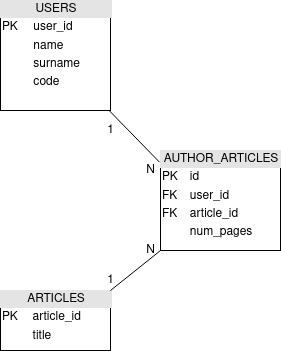
A questo punto, è necessario creare una nuova classe che mapperà la tabella AUTHOR_ARTICLES:
@Entity
@Table(name = "AUTHOR_ARTICLES")
public class AuthorArticlesEntity implements JpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "user_id")
private UserEntity userEntity;
@ManyToOne
@JoinColumn(name = "article_id")
private ArticleEntity articleEntity;
//getters, setters, equals, hashcode
}
La classe UserEntity avrà una collezione di tipo AuthorArticlesEntity e non più di tipo ArticleEntity, in relazione one to many invece che many to many. Vale lo stesso discorso per ArticleEntity.
Questa stessa strategia può essere adottata anche quando abbiamo bisogno di mappare una tabella d'associazione che mette in relazione più di due tabelle.
Conclusioni
In questo primo articolo su JPA abbiamo visto come mappare nella giusta maniera tutte le relazioni con JPA in modo bi-direzionale.
Potete trovare il progetto completo sul mio github a questo link: JPA Project
Articoli su JPA: JPA