
In questo tutorial vedremo come sviluppare un'applicazione event-driven e broker-agnostic utilizzando Spring Cloud Stream, sfruttando lo stesso codice per interagire sia con Apache Kafka che con RabbitMQ. Successivamente, approfondiremo l'aggiunta di configurazioni specifiche per Kafka e la gestione degli errori.
L'applicazione che realizzeremo simulerà l'invio e la ricezione di eventi generati da un sensore di temperatura. Analizzeremo come implementare Producer e Consumer sia in modalità imperativa che reattiva, adottando le funzionalità offerte da Spring Cloud Stream.
Un po' di teoria
Cos'è Spring Cloud Stream
Spring Cloud Stream è un modulo del framework Spring che combina le funzionalità di Spring Integration (dedicato all'implementazione dei pattern di integrazione) con la semplicità e la configurabilità di Spring Boot.
L'obiettivo principale di questo modulo è consentire agli sviluppatori di focalizzarsi esclusivamente sulla logica di business delle applicazioni event-driven, eliminando la complessità legata alla gestione del codice specifico per i diversi sistemi di messaggistica.
Con Spring Cloud Stream, è possibile scrivere codice per produrre e consumare messaggi su Apache Kafka, mantenendo la compatibilità con altri broker come RabbitMQ, AWS Kinesis, AWS SQS, Azure Event Hubs e molti altri, senza necessità di modifiche al codice.
Componenti di Spring Cloud Stream
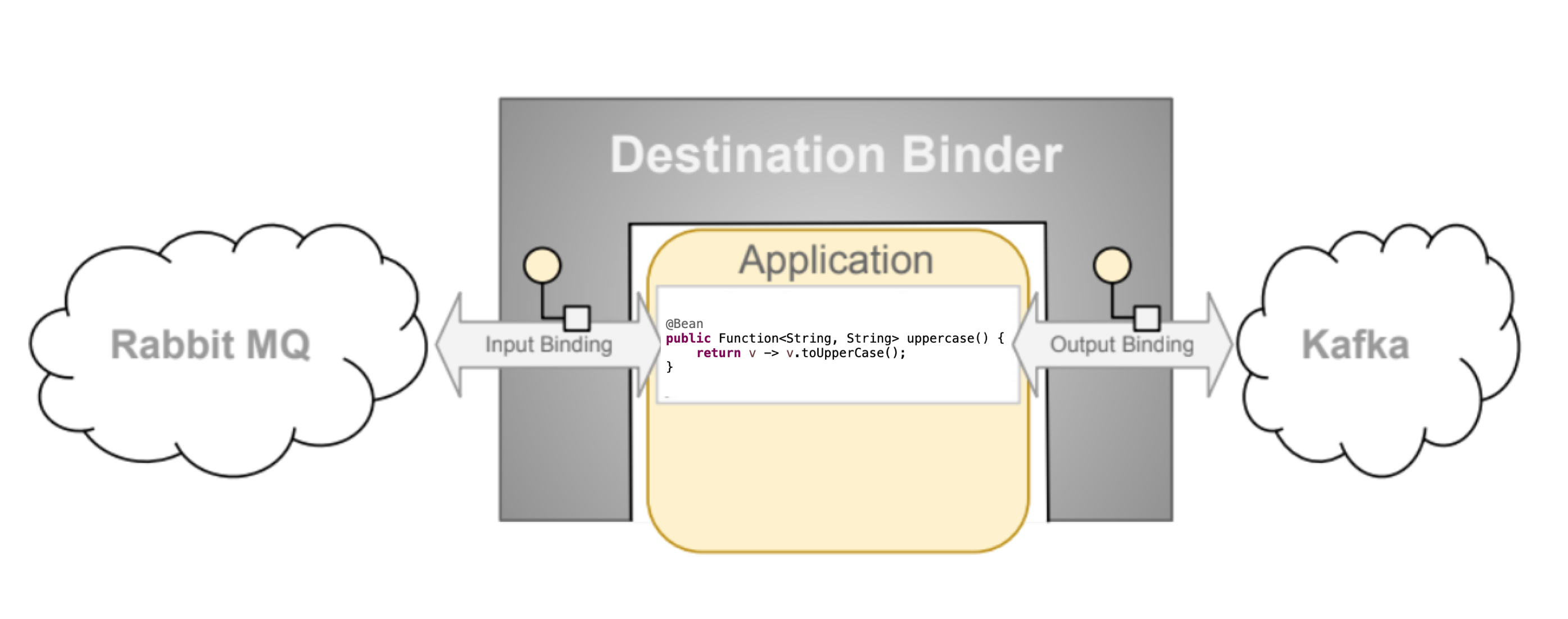
Spring Cloud Stream ha tre componenti principali:
- Destination Binder: il componente che fornisce l'integrazione con i sistemi di messaggi esterni come RabbitMQ o Kafka.
- Binding: Un bridge tra il sistema di messaggi esterno e i producer/consumer forniti dall'applicazione.
- Message: La struttura dati usata dai producer/consumer per comunicare con i Destination Binders.
 |
|---|
| Immagine presa da https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/spring-cloud-stream.html#spring-cloud-stream-reference |
Dall'immagine sopra si può notare che i bindings sono di input e di output. Possiamo combinare più binders; ad esempio potremmo leggere un messaggio da RabbitMQ e scriverlo su Kafka, creando una semplice funzione Java (a breve approfondiremo questa tematica).
Lo sviluppatore potrà concentrarsi unicamente sulla Business Logic nella forma di functions, dopodiché quando sceglierà il sistema di messaggi da utilizzare, dovrà importare la dipendenza del binder scelto.
Esistono binder gestiti direttamente da Spring Cloud Stream come Apache Kafka, RabbitMQ, Amazon Kinesis e altri gestiti da maintainers esterni come Azure EventHubs, Amazon SQS, etc. Comunque, Spring Cloud Stream permette di creare binders personalizzati in modo semplice.
Spring Cloud Stream integra inoltre le funzionalità di Partition e Message Groups speculari a quelli di Apache Kafka.
Questo significa che il framework mette a disposizione queste due funzionalità per qualsiasi sistema di messaggi scelto
(quindi ad esempio si avranno a disposizione anche se si utilizza RabbitMQ, nonostante questo sistema non li supporta nativamente).
Spring Cloud Stream da Spring Cloud Function
Spring Cloud Stream si basa su Spring Cloud Function, consentendo di scrivere la business logic utilizzando semplici funzioni. Il framework sfrutta le tre classiche interfacce di Java:
- Supplier: una funzione che produce un output ma non riceve input; spesso chiamata producer, publisher, source .
- Consumer: una funzione che riceve un input ma non produce output; nota anche come subscriber o sink.
- Function: una funzione che ha sia input che output, nota anche come processor.
La versione precedente di Spring Cloud Stream, non adottando Spring Cloud Function, rendeva il framework meno intuitivo e più complesso da utilizzare.
Questo è un esempio di processor che prende in input una stringa e la trasforma in upperCase, nella versione precedente del modulo:
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public String handle(Strign value) {
return value.toUpperCase();
}
Lo stesso esempio, con la versione attuale:
@Bean
public Function<String, String> uppercase(Strign value) {
return v -> v.toUpperCase();
}
Adesso un po' di pratica!
Primo passo: Creazione dello scheletro del progetto da Spring Initializr
Creiamo lo scheletro del progetto utilizzando Spring Initializr, accedendo al sito web dedicato o eseguendo il seguente comando direttamente da terminale:
curl https://start.spring.io/starter.zip \
-d groupId=com.vincenzoracca \
-d artifactId=spring-cloud-stream \
-d name=spring-cloud-stream \
-d packageName=com.vincenzoracca.springcloudstream \
-d dependencies=webflux,kafka,cloud-stream,lombok \
-d javaVersion=21 \
-d bootVersion=3.4.1 \
-d type=maven-project -o spring-cloud-stream.zip
Una volta estratto l'archivio ZIP, analizziamo il file pom.xml, con particolare attenzione alle seguenti dipendenze:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
La prima dipendenza rappresenta il modulo principale di Spring Cloud Stream, che fornisce l'infrastruttura per lo sviluppo di applicazioni event-driven. La seconda dipendenza aggiunge il binder specifico per Kafka, consentendo di collegare l'applicazione a un broker Kafka. Infine, la terza dipendenza fornisce il supporto diretto per le API di Spring Kafka, necessarie per interazioni più avanzate con Kafka.
Secondo passo: Creazione del model per il messaggio
Creiamo un sottopackage model e definiamo il seguente record:
public record SensorEvent(
String sensorId,
Instant timestampEvent,
Double degrees
)
{}
Questo record rappresenta il messaggio prodotto da un sensore di temperatura, contenente l'identificativo del sensore, il timestamp dell'evento e la temperatura rilevata.
Terzo passo: Creazione di un consumer
Creiamo un sottopackage event e al suo interno definiamo la seguente classe:
@Configuration
@Slf4j
@RequiredArgsConstructor
public class SensorEventFunctions {
@Bean
public Consumer<SensorEvent> logEventReceived() {
return sensorEvent ->
log.info("Message received: {}", sensorEvent);
}
}
Analizziamo il codice:
- La classe è annotata con
@Configuration, indicando che contiene uno o più bean (metodi annotati con@Bean). - Il metodo
logEventReceivedrappresenta il consumer: una semplice funzione Java di tipoConsumerche stampa il messaggio ricevuto. - In Spring Cloud Function, per attivare una funzione, è necessario annotarla con
@Bean.
📢 Nota: Avete visto riferimenti a Kafka? Esatto, nessuno! 🤭 Spring Cloud Stream si occupa di tutto, rendendo il codice completamente broker-agnostic.
Quarto passo: Creazione di un producer
Nella stessa classe, aggiungiamo un metodo per definire un producer:
@Bean
public Supplier<SensorEvent> sensorEventProducer() {
final RandomGenerator random = RandomGenerator.getDefault();
return () -> new SensorEvent(
"2",
Instant.now(),
random.nextDouble(1.0, 31.0)
);
}
A differenza delle funzioni di tipo Consumer e Function, che vengono attivate ogni volta che un messaggio arriva sul
canale di destinazione (ad esempio un topic Kafka), le funzioni di tipo Supplier non ricevono dati in ingresso. Per questo motivo,
sono attivate da un poller configurato da Spring Cloud Stream.
Il poller predefinito richiama il metodo del producer ogni secondo. È possibile personalizzare l'intervallo di polling (fixed delay) in due modi:
- Globalmente, per tutti i poller dell'applicazione, utilizzando la proprietà:
spring.integration.poller.fixed-delay. - Specificatamente per un producer, attraverso la proprietà:
spring.cloud.stream.bindings.<binding-name>.producer.poller.fixed-delay.
Nel nostro caso, configureremo il poller nel passo successivo per richiamare il metodo del producer ogni cinque secondi, con un ritardo iniziale di un secondo.
Il producer dell'esempio simula l'invio periodico di un messaggio generato da un sensore con:
sensorIdpari a2,- un timestamp corrente,
- una temperatura casuale compresa tra
1.0e31.0.
Abbiamo completato la scrittura del codice! Non è stato necessario implementare manualmente serializzatori o deserializzatori: Spring Cloud Stream gestisce automaticamente questi dettagli. Questo approccio consente di concentrarsi esclusivamente sulla logica applicativa, senza preoccuparsi delle complessità legate al broker di messaggistica.
Quinto passo: Configurazione di Spring Cloud Stream
Rinominiamo il file application.properties in application.yml e aggiungiamo le seguenti configurazioni:
spring:
application:
name: spring-cloud-stream
cloud:
function:
definition: logEventReceived;sensorEventProducer
stream:
bindings:
logEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
sensorEventProducer-out-0: #a producer
destination: sensor_event_topic
producer:
poller:
fixed-delay: 5000
initial-delay: 1000
Analizziamo il file:
spring.cloud.function.definition: Specifica le funzioni dell’applicativo annotate con @Bean. Le funzioni sono separate da un punto e virgola.spring.cloud.stream.bindings: Mappa ogni producer/consumer alla sua destinazione (in questo caso il nome del topic Kafka). Segue la convenzione di naming:- Per i binding di input:
<functionName>-in-<index> - Per i binding di output:
<functionName>-out-<index> - Il campo
indexè solitamente0quando utilizziamo il concetto di message groups. Se una funzione ha più canali di input o output, il campo index viene utilizzato per distinguerli.
- Per i binding di input:
- Il consumer
logEventReceivedinclude anche il campogroup, che definisce il nome del Message Group. Questo permette ai consumer dello stesso gruppo di leggere messaggi da partizioni diverse, abilitando lo scaling orizzontale. - Il producer
sensorEventProducerè configurato per attivare il poller ogni cinque secondi con un ritardo iniziale di un secondo.
Sesto passo: Avvio di Kafka in locale con Docker
Utilizziamo questo file Docker Compose, in modo tale da avviare Kafka in locale tramite Docker:
---
version: '3'
services:
broker:
image: confluentinc/cp-kafka:7.6.1
hostname: broker
container_name: broker
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: |
CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: |
PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@broker:29093'
KAFKA_LISTENERS: |
PLAINTEXT://broker:29092,CONTROLLER://broker:29093,PLAINTEXT_HOST://0.0.0.0:9092
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qj'
Non è necessario eseguire manualmente alcun comando per avviare Docker Compose.
A partire dalla versione 3.1 di Spring Boot, con la dipendenza spring-boot-docker-compose, Docker Compose viene avviato automaticamente durante l’avvio dell’applicazione.
Settimo passo: Avvio dell'applicazione
Avviamo l'applicazione e analizziamo i log. Vedremo un messaggio simile registrato ogni cinque:
Message received: SensorEvent[sensorId=2,
timestampEvent=2023-02-27T17:40:08.367719Z, degrees=30.0]
Il producer invia un messaggio ogni cinque secondi, e il consumer li riceve e li logga correttamente.
Ottavo passo: Producer programmatico con Spring Cloud Stream
Ci sono scenari in cui la fonte dei dati proviene da un sistema esterno che non è un binder. Ad esempio, la fonte potrebbe
essere un classico endpoint REST. Come possiamo integrare una fonte di questo tipo con il modello funzionale offerto da Spring Cloud Stream?
Spring Cloud Stream mette a disposizione un bean di tipo StreamBridge per questo caso d'uso!
Creiamo una bean Producer che utilizza la classe StreamBridge per inviare un messaggio.
Questo producer verrà invocato da una API REST:
@Component
@RequiredArgsConstructor
public class ProducerSensorEvent {
private final StreamBridge streamBridge;
public boolean publishMessage(SensorEvent message) {
return streamBridge.send(
"sensorEventAnotherProducer-out-0",
message
);
}
}
//REST API
@RestController
@RequestMapping("sensor-event")
@RequiredArgsConstructor
public class SensorEventApi {
private final ProducerSensorEvent producerSensorEvent;
@PostMapping
public Mono<ResponseEntity<Boolean>> sendDate(
@RequestBody Mono<SensorEvent> sensorEvent) {
return sensorEvent
.map(producerSensorEvent::publishMessage)
.map(ResponseEntity::ok);
}
}
Niente di più semplice. Il metodo send della classe StreamBridge prende in input il nome del binding e il messaggio da inviare.
Ovviamente, dobbiamo aggiungere questo nuovo binding nel file application.yml solo nella sezione bindings
(non dobbiamo aggiungerlo nella sezione function perché banalmente non è un funzione):
sensorEventAnotherProducer-out-0: #another producer
destination: sensor_event_topic
Per inviare il messaggio, possiamo effettuare una chiamare REST del genere: http POST :8080/sensor-event sensorId=1 timestampEvent=2023-02-26T15:15:00Z degrees=26.0
Sostituzione di Kafka con RabbitMQ
Per utilizzare RabbitMQ al posto di Apache Kafka, ci basta sostituire le dipendenze relative alle API e al binder di Kafka, con quelle dedicate a RabbitMQ:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
Per eseguire RabbitMQ in locale, sostituisci nel file docker-compose.yml il service di Kafka con quello di RabbitMQ:
rabbitmq:
image: rabbitmq:3-management
container_name: rabbitmq
ports:
- 5672:5672
- 15672:15672
Avvia l'applicazione e dai uno sguardo ai log:
Created new connection: rabbitConnectionFactory.publisher ...
Message received: SensorEvent[sensorId=2, timestampEvent=2025-01-01T17:30:18.237359Z, degrees=22.275162304088724]
Message saving: SensorEvent[sensorId=2, timestampEvent=2025-01-01T17:30:18.237359Z, degrees=22.275162304088724]
Message saved with id: 2
L'applicazione sta correttamente inviando e ricevendo messaggi utilizzando RabbitMQ al posto di Kafka, senza la necessità di modificare il codice!
Personalizzare properties per Kafka
Per customizzare le configurazioni di Kafka, è sufficiente utilizzare le properties con prefisso spring.cloud.stream.kafka.binder.
Possiamo aggiungere configurazioni globali, configurazioni limitate a tutti i producer (spring.cloud.stream.kafka.binder.producerProperties) o
specifico per un singolo producer (spring.cloud.stream.kafka.bindings.<channelName>.producer..).
Lo stesso per i consumer.
Ad esempio:
spring:
application:
name: spring-cloud-stream
cloud:
function:
definition: logEventReceived|saveInDBEventReceived;sensorEventProducer
stream:
kafka:
binder:
brokers: localhost:9092
# kafka-properties: global props
# boootstrap.server: localhost:9092 Global props
consumerProperties: #consumer props
max.poll.records: 250
# producerProperties: producer props
bindings:
logEventReceivedSaveInDBEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
sensorEventProducer-out-0: #a producer
destination: sensor_event_topic
sensorEventAnotherProducer-out-0: #another producer
destination: sensor_event_topic
Spring Cloud Stream Reactive
Con la nuova versione di Spring Cloud Stream, non c'è necessità di importare una nuova di dipendenza.
La versione reactive diventa:
@Bean
public Function<Flux<SensorEvent>, Mono<Void>> logEventReceived() {
return fluxEvent -> fluxEvent
.doOnNext(sensorEvent ->
log.info("Message received: {}", sensorEvent))
.then();
}
@PollableBean
public Supplier<Flux<SensorEvent>> sensorEventProducer() {
final RandomGenerator random = RandomGenerator.getDefault();
return () -> Flux.just(new SensorEvent(
"2",
Instant.now(),
random.nextDouble(1.0, 31.0))
);
}
Nota che il consumer ora è una Function che prende in input un Flux di messaggi e restituisce un Mono<Void>.
Tuttavia, può essere scritto anche in questo modo:
@Bean
public Consumer<Flux<SensorEvent>> logEventReceived() {
return fluxEvent -> {
fluxEvent
.doOnNext(sensorEvent ->
log.info("Message received: {}", sensorEvent))
.subscribe();
};
}
Siccome in WebFlux "niente succede se il flusso non è sottoscritto", qui siamo costretti a esplicitare il subscribe.
Nella modalità Reactive quindi, per creare un consumer, possiamo utilizzare o l'interfaccia Function o quella Consumer.
Per quanto riguarda il producer, Spring Cloud Stream nella modalità Reactive, non fa partire automaticamente il polling di un
secondo, perché lo stream di un Flux potrebbe essere potenzialmente infinito. Comunque, puoi triggerare un Supplier reattivo
annotando la funzione con @PollableBean. Questo abilita un poller ogni secondo sulla funzione. Puoi modificare le tempistiche del poller
utilizzando le stesse properties viste nella versione imperativa.
Functions composition in Spring Cloud Function
In Spring Cloud Function, possiamo concatenare pìù funzioni. Ad esempio, oltre a loggare il messaggio ricevuto, vogliamo anche salvarlo a DB. Per fare cioè scriviamo un'altra funzione che prende in input il messaggio e lo salva a DB:
@Bean
public Function<Flux<SensorEvent>, Mono<Void>> saveInDBEventReceived() {
return fluxEvent -> fluxEvent
.doOnNext(sensorEvent ->
log.info("Message saving: {}", sensorEvent))
.flatMap(sensorEvent ->
sensorEventDao.save(Mono.just(sensorEvent)))
.then();
}
a quel punto, modifichiamo la funzione di log in modo tale da restituire di nuovo il messaggio, dopo averlo loggato. L'output della funzione logEventReceived sarà l'input della funzione saveInDBEventReceived:
@Bean
public Function<Flux<SensorEvent>, Flux<SensorEvent>> logEventReceived() {
return fluxEvent -> fluxEvent
.doOnNext(sensorEvent ->
log.info("Message received: {}", sensorEvent));
}
Per concatenare le due funzioni, utilizziamo l'operatore | (pipe) nell'application.yml:
spring:
application:
name: spring-cloud-stream
cloud:
function:
definition: logEventReceived|saveInDBEventReceived;sensorEventProducer
stream:
bindings:
logEventReceivedSaveInDBEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
sensorEventProducer-out-0: #a producer
destination: sensor_event_topic
sensorEventAnotherProducer-out-0: #another producer
destination: sensor_event_topic
Notiamo due cose:
- Le due funzioni
logEventReceivedesaveInDBEventReceivedsono concatenate con la pipe. L'output della prima funzione diventa l'input della seconda. - Il nome del binding diventa
logEventReceivedSaveInDBEventReceived, cioè la concatenazione dei nomi delle due funzioni.
Error Handling: retries e DLQ
Possiamo personalizzare la gestione degli errori configurando una politica di retry per specifiche eccezioni e implementando la redirezione verso un Dead Letter Queue (DLQ) per i messaggi scartati. Questi includono sia i messaggi che non soddisfano i criteri della politica di retry sia quelli che hanno esaurito il numero massimo di tentativi.
Per testare l'Error Handling in Spring Cloud Stream, simuliamo un errore quando l'evento ricevuto riporta una temperatura di 10 gradi. Modifichiamo il codice della classe DAO in questo modo:
public Mono<SensorEvent> save(Mono<SensorEvent> sensorEventMono) {
return sensorEventMono
.doOnNext(sensorEvent ->
log.info("Message saving: {}", sensorEvent))
.map(sensorEvent -> {
if (sensorEvent.degrees() == 10.0)
throw new RuntimeException("Error in saveMessage");
return sensorEvent;
})
.doOnNext(sensorEvent ->
memoryDB.put(sensorEvent.sensorId(), sensorEvent))
.doOnNext(sensorEvent ->
log.info("Message saved with id: {}", sensorEvent.sensorId()));
}
Inoltre, sia per la versione imperativa che per quella reactive, la gestione della DLQ non funziona con la composizione delle funzioni di Spring Cloud Function. Per quanto riguarda la versione imperativa, possiamo comporre manualmente le due funzioni in questo modo:
@Bean
public Function<SensorEvent, Void> logEventReceivedSaveInDBEventReceived() {
return logEventReceived().andThen(sensorEvent -> {
saveInDBEventReceived().accept(sensorEvent);
return null;
});
}
Ricorda di eliminare l'annotazione @Bean sulle singole funzioni e di sostituire il valore della property spring.cloud.function.definition
con la nuova funzione logEventReceivedSaveInDBEventReceived.
Per quanto riguarda la versione reattiva, approfondiremo nel sottoparagrafo dedicato.
Versione imperativa
Un consumer in Spring Cloud Stream, nella versione imperativa, tenterà di elaborare in totale tre volte il messaggio,
nel caso quest'ultimo sollevi una eccezione.
Il valore di default di maxAttempts può essere sovrascritto in questo modo:
bindings:
logEventReceivedSaveInDBEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
consumer:
max-attempts: 3 #default is 3
Puoi anche decidere su quali eccezioni effettuare le retries popolando la property retryable-exceptions in questo modo:
bindings:
logEventReceivedSaveInDBEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
consumer:
max-attempts: 3 #default is 3
retryable-exceptions:
java.lang.RuntimeException: true #retryable
java.lang.IllegalArgumentException: false #not retryable
Se l'eccezione non è esplicitata in retryable-exceptions, sarà gestita con la retry.
Per quanto riguarda le DLQ, anche questa funzionalità è gestita out-of-box da Spring Cloud Stream, nella versione imperativa. Basta aggiungere le seguenti properties:
cloud:
function:
definition: logEventReceivedSaveInDBEventReceived;sensorEventProducer
stream:
kafka:
binder:
brokers: localhost:9092
consumerProperties: #consumer props
max.poll.records: 250
bindings:
logEventReceivedSaveInDBEventReceived-in-0:
consumer:
enable-dlq: true
dlq-name: sensor_event_topic_dlq
Con enable-dlq indichiamo a Spring che vogliamo che il consumer abbia una DLQ.
Con dlq-name diamo il nome del topic DLQ.
Per provare l'Error Handling, possiamo inviare un messaggio dalla CLI di Kafka.
Con Docker e il progetto in esecuzione, esegui il comando
docker exec -it broker bash.Esegui il comando
/bin/kafka-console-consumer --bootstrap-server broker:9092 --topic sensor_event_topic_dlq.
In questo modo vedrai il contenuto della coda DLQ.Apri un'altra shell ed esegui lo stesso comando del passo 1.
Esegui il comando
/bin/kafka-console-producer --bootstrap-server broker:9092 --topic sensor_event_topic.Ora puoi inviare il seguente messaggio:
{ "sensorId": "prova-id", "timestampEvent": "2023-06-09T18:40:00Z", "degrees": 10.0 }
Vedremo il seguente messaggio di log:
Message received: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
Message saving: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
Message received: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
Message saving: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
Message received: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
Message saving: SensorEvent[sensorId=prova-id, timestampEvent=2023-06-09T18:40:00Z, degrees=10.0]
org.springframework.messaging.MessageHandlingException: error occurred in message handler
[org.springframework.cloud.stream.function.FunctionConfiguration$FunctionToDestinationBinder$1@5c81d158],
failedMessage=GenericMessage [payload=byte[85], headers={kafka_offset=99,
kafka_consumer=org.apache.kafka.clients.consumer.KafkaConsumer@306f6122, deliveryAttempt=3,
kafka_timestampType=CREATE_TIME, kafka_receivedPartitionId=0, kafka_receivedTopic=sensor_event_topic,
kafka_receivedTimestamp=1686585227257, contentType=application/json, kafka_groupId=spring-cloud-stream}]
...
Caused by: java.lang.RuntimeException: Error in saveMessage
at com.vincenzoracca.springcloudstream.dao.SensorEventInMemoryDao.lambda$save$1(SensorEventInMemoryDao.java:26)
at com.vincenzoracca.springcloudstream.event.SensorEventImperativeFunctions.lambda$saveInDBEventReceived$2(SensorEventImperativeFunctions.java:45)
...
o.a.k.clients.producer.ProducerConfig : ProducerConfig values: ...
Come si evince dai log, il messaggio viene elaborato tre volte in totale prima di andare definitivamente in errore ed essere spedito in DLQ (puoi controllare anche la coda DLQ).
Versione reactive
Con la versione reactive di Spring Cloud Stream, quelle properties settate in precedenza non funzionano!
Un modo per gestire retries e DLQ potrebbe essere:
- Avere il consumer con un una sola funziona (no concatenazioni).
- Wrappare la business logic del consumer in una funzione flatMap, per avere a disposizione il messaggio da mandare in DLQ.
- Gestire le retries con la funzione retry di Reactor.
- Creare un channel per la DLQ e mandare il messaggio in errore a quest'ultimo.
Ecco il consumer reactive modificato per gestire retries e DLQ:
private static final String DLQ_CHANNEL = "sensorEventDlqProducer-out-0";
@Bean
public Function<Flux<SensorEvent>, Mono<Void>> logEventReceivedSaveInDBEventReceived() {
return fluxEvent -> fluxEvent
.flatMap(this::consumeMessage)
.then();
}
private Mono<Void> consumeMessage(SensorEvent message) {
return logEventReceived().andThen(saveInDBEventReceived()).apply(Flux.just(message))
.retry(2)
.onErrorResume(throwable ->
dlqEventUtil.handleDLQ(message, throwable, DLQ_CHANNEL));
}
DlqEventUtil è una classe di utility che semplicemente invia i messaggi in una DLQ:
@Component
@Slf4j
@RequiredArgsConstructor
public class DlqEventUtil {
private final StreamBridge streamBridge;
public <T> Mono<Void> handleDLQ(T message, Throwable throwable, String channel) {
log.error("Error for message: {}", message, throwable);
streamBridge.send(channel, message);
return Mono.empty();
}
}
Il file application.yml diventa:
spring:
application:
name: spring-cloud-stream
cloud:
function:
definition: logEventReceivedSaveInDBEventReceived;sensorEventProducer
stream:
kafka:
binder:
brokers: localhost:9092
consumerProperties: #consumer props
max.poll.records: 250
bindings:
logEventReceivedSaveInDBEventReceived-in-0: #a consumer
destination: sensor_event_topic
group: ${spring.application.name}
sensorEventProducer-out-0: #a producer
destination: sensor_event_topic
sensorEventAnotherProducer-out-0: #another producer
destination: sensor_event_topic
sensorEventDlqProducer-out-0: #DLQ producer
destination: sensor_event_topic_dlq
Testing Spring Cloud Stream applications
Quando abbiamo importato il progetto da Spring Initializr, nel pom è stata aggiunta anche la seguente dipendenza:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-binder</artifactId>
<scope>test</scope>
</dependency>
Grazie a essa, possiamo testare facilmente i nostri consumer e producer. Vediamo come:
@SpringBootTest
@ActiveProfiles("reactive")
@Import(TestChannelBinderConfiguration.class)
class SensorEventTestsIT {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Autowired
private ObjectMapper objectMapper;
@Autowired
private ProducerSensorEvent producerSensorEvent;
@Autowired
private SensorEventDao sensorEventDao;
@Test
public void produceSyncMessageTest() throws IOException {
SensorEvent sensorEvent = new SensorEvent("3", Instant.now(), 15.0);
producerSensorEvent.publishMessage(sensorEvent);
byte[] payloadBytesReceived = output.receive(100L, "sensor_event_topic").getPayload();
assertThat(objectMapper.readValue(payloadBytesReceived, SensorEvent.class)).isEqualTo(sensorEvent);
}
@Test
public void producePollableMessageTest() throws IOException {
byte[] payloadBytesReceived = output.receive(5000L, "sensor_event_topic").getPayload();
SensorEvent sensorEventMessageReceived = objectMapper.readValue(payloadBytesReceived, SensorEvent.class);
assertThat(sensorEventMessageReceived.sensorId()).isEqualTo("2");
assertThat(sensorEventMessageReceived.degrees()).isBetween(1.0, 30.0);
}
@DirtiesContext(methodMode = DirtiesContext.MethodMode.BEFORE_METHOD)
@Test
public void consumeMessageTest() throws IOException {
SensorEvent sensorEvent = new SensorEvent("3", Instant.now(), 15.0);
byte[] payloadBytesSend = objectMapper.writeValueAsBytes(sensorEvent);
input.send(new GenericMessage<>(payloadBytesSend), "sensor_event_topic");
StepVerifier
.create(sensorEventDao.findAll())
.expectNext(sensorEvent)
.expectComplete()
.verify();
}
}
Importando la classe TestChannelBinderConfiguration, Spring ci fornire dei bean di InputDestination e OutputDestination,
che possiamo utilizzare per testare consumer e producer rispettivamente.
Non abbiamo bisogno del binder reale; il framework ci fornisce un binder di test.
Analizziamo uno per uno i test:
- Nel test
produceSyncMessageTest, utilizziamo il nostro producer sincrono per inviare un messaggio.
Verifichiamo con l'OutputDestination che il messaggio sia stato effettivamente inviato sulla destination (topic Kafka). - Nel test
producePollableMessageTest, non inviamo nessun messaggio esplicitamente, poiché il producer è di tipo pollable. Aspettiamo cinque secondi per verificare che il messaggio sia stato inviato correttamente (siccome il polling è di cinque secondi). - Nel test
consumeMessageTest, inviamo con l'OutputDestination un messaggio sul topic Kafka e in seguito verifichiamo che lo stesso messaggio sia stato salvato a DB.
Inoltre il metodo è annotato con@DirtiesContext(methodMode = DirtiesContext.MethodMode.BEFORE_METHOD), per pulire il contesto (e quindi il DB), prima che venga invocato il metodo.
Conclusioni
In questo articolo abbiamo esplorato l'utilizzo di Spring Cloud Stream per lo sviluppo di applicazioni event-driven. La possibilità di concentrarsi esclusivamente sulla business logic, scrivendo semplici funzioni Java indipendenti dal broker utilizzato, rende questo framework estremamente interessante. Abbiamo evidenziato come sia possibile passare da Kafka a RabbitMQ senza alcuna modifica al codice: una flessibilità davvero notevole. Inoltre, è possibile integrare diversi binder all'interno della stessa applicazione, ampliando ulteriormente le opportunità di utilizzo.
Trovate il codice completo sul mio repo di GitHub al seguente link: GitHub.
Altri articoli su Spring: Spring.
Articoli su Docker: Docker.
Libri consigliati su Spring, Docker e Kubernetes:
- Cloud Native Spring in Action: https://amzn.to/3xZFg1S
- Pro Spring 6: An In-Depth Guide to the Spring Framework: https://amzn.to/4g8VPff
- Pro Spring Boot 3: An Authoritative Guide With Best Practices: https://amzn.to/4hxdjDp
- Docker: Sviluppare e rilasciare software tramite container: https://amzn.to/3AZEGDI
- Kubernetes. Guida per gestire e orchestrare i container: https://amzn.to/3EdA94v
Riferimenti
- Cloud Native Spring in Action, capitolo 10
- https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/
- https://cloud.spring.io/spring-cloud-stream-binder-kafka/spring-cloud-stream-binder-kafka.html#_configuration_options
- https://cloud.spring.io/spring-cloud-stream/multi/multi_spring-cloud-stream-overview-binders.html