
Spring Batch è un potente modulo di Spring che viene usato per eseguire job.
Un problema abbastanza comune è gestire istanze multiple di uno stesso job poiché
Spring Batch non ha una gestione di lock di default.
Ci sono vari modi per gestire questa situazione, tutti però fanno più o meno la stessa cosa:
le istanze multiple condividono uno stesso database che gestisce la sincronizzazione tra i nodi/istanze.
Più precisamente, quando deve essere eseguito un job
(magari al trigger di una cron), l'istanza controlla nel database se quel job è già stato
"bloccato" da un'altra istanza; se si, allora l'istanza non eseguirà il job.
Ci sono più librerie che risolvono il problema della gestione di istanze multiple di un job:
se già all'interno del progetto viene usato lo scheduler di Quarz, allora si può usare questa stessa
libreria; altrimenti Shedlock, che fa prettamente locking di job, potrebbe fare al caso nostro.
Il tutorial farà riferimento ad un batch che leggerà un file csv e scriverà il contenuto in una tabella USER di un database MySQL.
Prerequisiti
- Aver installato una jdk (useremo la versione 8 ma va bene anche una successiva).
- Aver installato maven (https://maven.apache.org/install.html).
- Aver installato un DB che sincronizzerà 2 istanze della stessa app (noi useremo un'immagine docker di MySQL).
- I nodi devono raggiungere lo stesso DB (nel tutorial eseguiremo 2 istanze in localhost).
Primo passo: Creare le tabelle USER e SHEDLOCK nel database:
CREATE TABLE USER (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(250) NOT NULL,
surname VARCHAR(250) NOT NULL,
address VARCHAR(250) DEFAULT NULL
);
CREATE TABLE SHEDLOCK (
name VARCHAR(64),
lock_until TIMESTAMP(3) NULL,
locked_at TIMESTAMP(3) NULL,
locked_by VARCHAR(255),
PRIMARY KEY (name)
)
Secondo passo: andare sul sito Spring Initializr
Questo sito creerà per noi uno scheletro di un'app Spring Boot con tutto quello che ci serve (basta cercare le dipendenze che ci servono nella sezione 'Dependencies'). Clicchiamo su 'ADD DEPENDENCIES' ed aggiungiamo le dipendenze riportate dall'immagine.
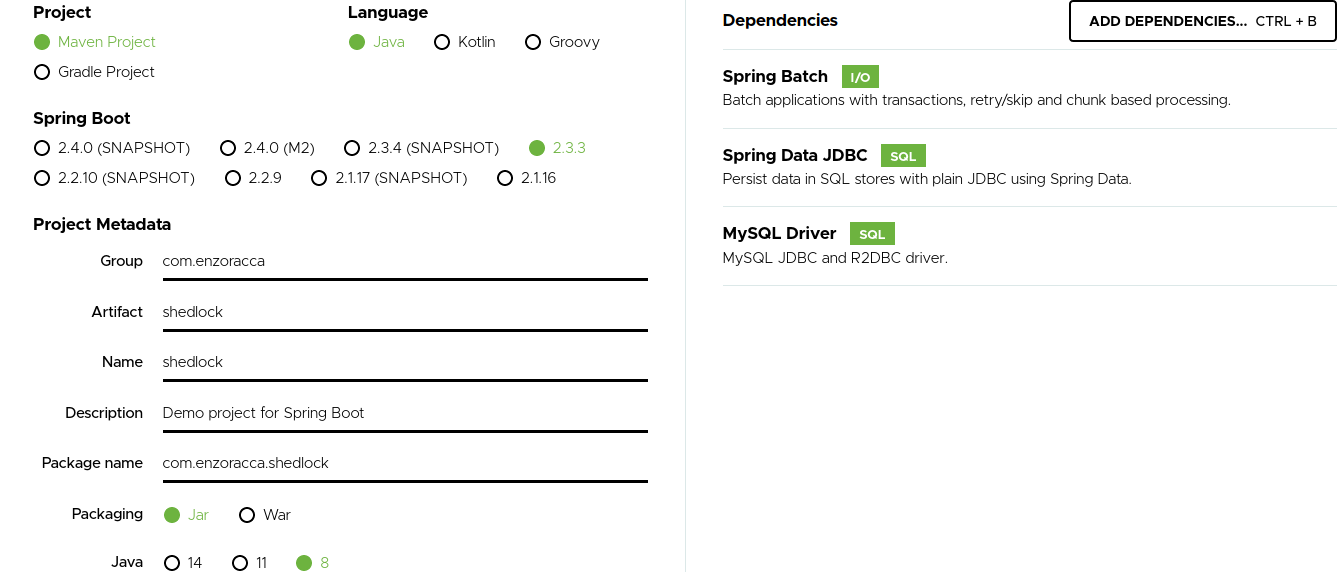
Cliccate su 'Generate' e unzippate il progetto.
Terzo passo: importiamo le dipendenze di Shedlock
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-spring</artifactId>
<version>4.14.0</version>
</dependency>
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-jdbc-template</artifactId>
<version>4.14.0</version>
</dependency>
Quarto passo: creiamo un model che mapperà una tabella del Database
Creiamo un sottopackage models e lì creiamo una classe Java che mapperà una tabella USER:
public class User implements Serializable {
private Long id;
private String name;
private String surname;
private String address;
//getter, setter, equals and hashcode
}
Quinto passo: creiamo la configurazione di Spring Batch
Abbiamo detto che il batch leggerà da un file csv e scriverà ogni riga letta su una tabella USER del DB.
Scriviamo un job molto banale all'interno del sottopackage config:
@Configuration
@EnableBatchProcessing
@EnableScheduling
public class BatchConfig {
private StepBuilderFactory stepBuilderFactory;
private JobBuilderFactory jobBuilderFactory;
private DataSource dataSource;
public BatchConfig(StepBuilderFactory stepBuilderFactory, JobBuilderFactory jobBuilderFactory, DataSource dataSource) {
this.stepBuilderFactory = stepBuilderFactory;
this.jobBuilderFactory = jobBuilderFactory;
this.dataSource = dataSource;
}
@Bean
FlatFileItemReader<User> itemReader() {
return new FlatFileItemReaderBuilder<User>()
.name("userItemReader")
.resource(new ClassPathResource("test-data.csv"))
.delimited()
.delimiter(";")
.names("name", "surname", "address")
.fieldSetMapper(new BeanWrapperFieldSetMapper<User>(){{
setTargetType(User.class);
}})
.build();
}
@Bean
JdbcBatchItemWriter<User> itemWriter() {
return new JdbcBatchItemWriterBuilder<User>()
.dataSource(dataSource)
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO USER (name, surname, address) VALUES (:name, :surname, :address)")
.build();
}
@Bean
Step step() {
return stepBuilderFactory.get("step")
.<User, User>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.build();
}
@Bean
Job job() {
return jobBuilderFactory.get("job")
.start(step())
.build();
}
}
Analizziamo il codice:
- @EnableBatchProcessing ci permette di importare delle configurazioni già pronte di Spring Batch (come i bean di JobBuilderFactory e JobBuilderFactory).
- @EnableScheduling ci permette di usare l'annotation @Scheduler dove verrà fornita una cron.
- Come implementazione di ItemReader usiamo FlatFileItemReader per leggere il file csv.
- Come implementazione di ItemWriter usiamo JdbcBatchItemWriter per scrivere su una tabella del DB.
Per ora nulla di nuovo; passiamo a configurare Shedlock.
Sesto passo: configuriamo Shedlock
Creiamo la classe di configurazione di Shedlock nel sottopackage config:
@Configuration
@EnableSchedulerLock(defaultLockAtMostFor = "1m")
public class ShedLockConfig {
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(
JdbcTemplateLockProvider.Configuration.builder()
.withJdbcTemplate(new JdbcTemplate(dataSource))
.withTableName("SHEDLOCK") //for mysql linux case-sensitive
.usingDbTime() // Works on Postgres, MySQL, MariaDb, MS SQL, Oracle, DB2, HSQL and H2
.build()
);
}
}
La configurazione mostrata è molto semplice; la classe da configurare è LockProvider:
- @EnableSchedulerLock(defaultLockAtMostFor = "1m") abilita lo scanning di tutte le annotation @SchedulerLock di Shedlock (spiegheremo dopo la funzione di defaultLockAtMostFor).
- forniamo il datasource dove Shedlock cercherà la tabella dedicata al locking dei Job.
- .withTableName("SHEDLOCK") specifica il nome della tabella di Shedlock dove la libreria inserirà i dati dei job(di default cerca una table chiamata "shedlock", in minuscolo).
- .usingDbTime() Shedlock userà il time del DB, senza questa opzione di default verrà usato il time del client dell'app. Questo è rischioso perché i client potrebbero avere time diversi.
Settimo passo: creiamo una classe Runner che eseguirà il Job ogni 2 minuti
@Component
public class BatchRunner {
private Job job;
private JobLauncher jobLauncher;
public BatchRunner(Job job, JobLauncher jobLauncher) {
this.job = job;
this.jobLauncher = jobLauncher;
}
@Scheduled(cron = "0 */2 * * * *")
@SchedulerLock(name = "TaskScheduler_scheduledTask",
lockAtLeastFor = "1m", lockAtMostFor = "1m")
public void run() throws Exception {
jobLauncher.run(job, new JobParametersBuilder().addDate("date", new Date()).toJobParameters());
}
}
Annotiamo il metodo run con @SchedulerLock. Quindi Shedlock controllerà il lock di questo metodo per ogni istanza.
Analizziamo i parametri lockAtMostFor e lockAtLeastFor:
- lockAtMostFor specifica il tempo massimo per cui deve essere mantenuto il lock. Questo è solo un fallback, quindi è utile quando un nodo muore, poiché di default quando il job termina, Shedlock rilascia il lock. Se non specifichiamo questo parametro nell'annotation @SchedulerLock, allora verrà usato il parametro di default (defaultLockAtMostFor = "1m" all'interno di @EnableSchedulerLock).
- lockAtLeastFor specifica il tempo minimo per cui deve essere mantenuto il lock. Ha lo scopo di impedire l'esecuzioni di job da più nodi in parallelo.
Ottavo passo: modifichiamo l'application.properties e creiamo un csv
spring.datasource.url=jdbc:mysql://localhost:3306/shedlock_DB?useSSL=false&serverTimezone=Europe/Rome
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.platform=mysql
spring.batch.job.enabled=false
spring.batch.initialize-schema=always
Creiamo all'interno di resources test-data.csv con questo contenuto:
Vincenzo;Racca;via Napoli
Pippo;Pluto;via Roma
Finito! Eseguiamo l'app con 2 istanze diverse
Buildiamo il progetto e copiamo il jar in una cartella chiamata "batch1" fuori dal progetto.
Copiamo poi il jar anche in una seconda cartella chiamata "batch2". All'interno di batch2 copiamo anche
l'application.properties e modifichiamo la property:
spring.batch.initialize-schema=never
Avviamo i jar di batch1 e batch2 e seguiamo i log:
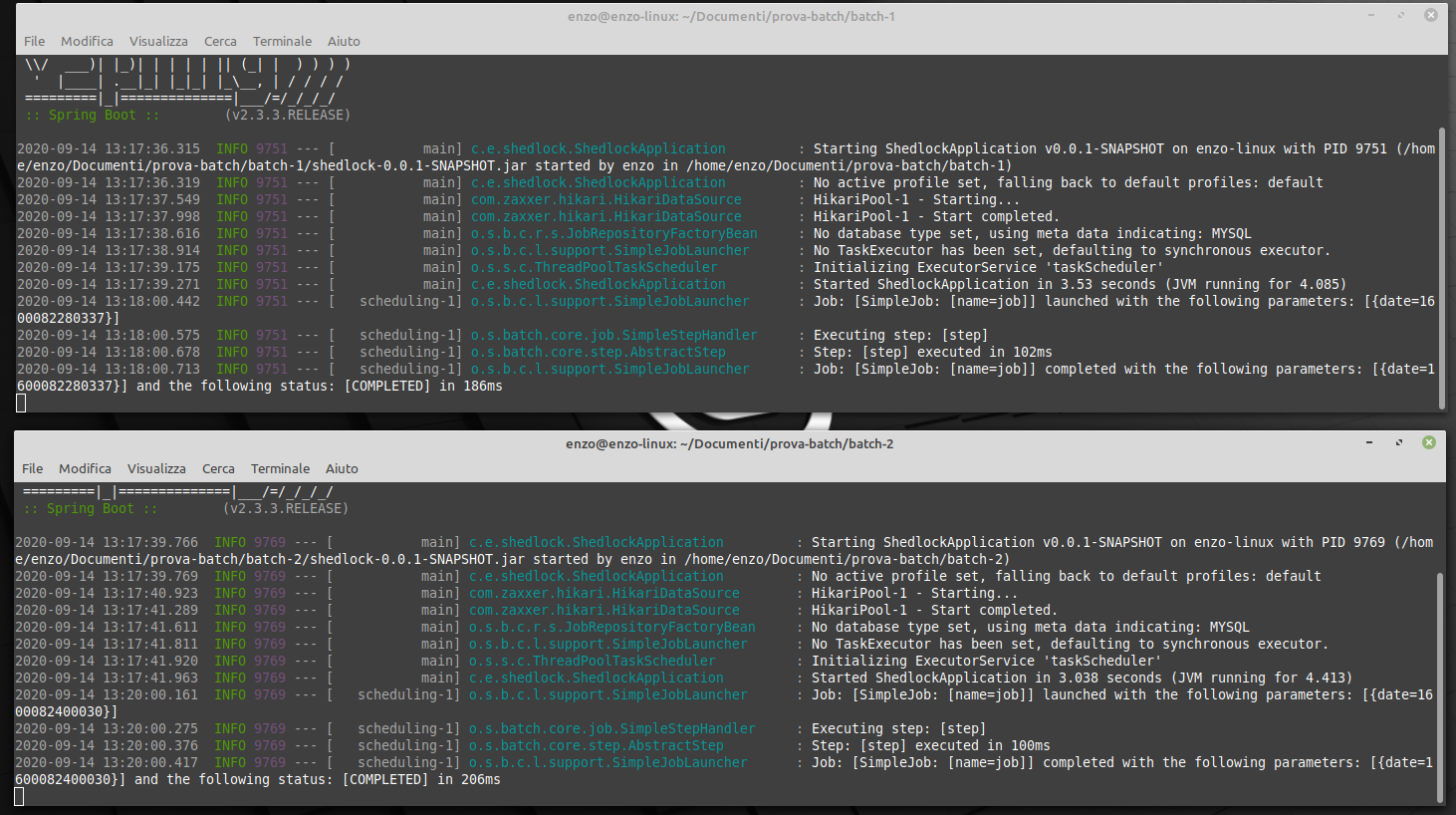
Conclusioni
Come dimostra l'immagine, i job non vengono eseguiti in parallelo. Infatti nei primi 2 minuti è stato eseguito dall'istanza 1 mentre nei successivi 2, dall'istanza 2. Se si provasse a stoppare un'istanza, il job continuerebbe a girare perché c'è ancora in funzione la seconda istanza.
Potete trovare il progetto completo sul mio github a questo link: Shedlock
Inoltre nel README.md del progetto github spiego come creare un container MySQL da un'immagine Docker.
Documentazione del progetto Shedlock: Shedlock Documentation
Articoli su Spring: Spring
Libri consigliati su Spring:
- Cloud Native Spring in Action: https://amzn.to/3xZFg1S
- Pro Spring 6: An In-Depth Guide to the Spring Framework: https://amzn.to/4g8VPff
- Pro Spring Boot 3: An Authoritative Guide With Best Practices: https://amzn.to/4hxdjDp