
In scenari batch ad alto volume, capita spesso di dover elaborare record che possono essere raggruppati secondo un criterio logico di partizione (ad esempio per utente, area geografica, categoria, ecc.). Organizzare l’elaborazione per partizioni può portare diversi vantaggi, soprattutto in termini di performance e gestione della concorrenza.
Con un approccio batch partizionato, è possibile:
- Raggruppare i record appartenenti alla stessa partizione per eseguire una sola volta operazioni comuni (come update su tabelle aggregate o chiamate esterne).
- Parallelizzare l’elaborazione tra partizioni indipendenti, migliorando il throughput complessivo del job.
In questo articolo ti mostro come utilizzare Spring Batch per costruire un job partizionato in grado di elaborare ogni partizione in parallelo, mantenendo al tempo stesso l’elaborazione sequenziale dei record all’interno di ciascuna partizione.
Il Problema
Durante una recente attività lavorativa, mi è capitato di dover implementare un job che leggesse dei record da una tabella
DynamoDB contenente informazioni sulle spedizioni.
Le spedizioni sono gestite da recapitisti distribuiti su diverse province: uno stesso recapitista può operare in più province.
Per questo motivo, ogni spedizione è identificata da una coppia logica recapitista-provincia, come mostrato di seguito:
| paper_delivery_id | created_at | delivery_driver_id | province |
|---|---|---|---|
| delivery-1 | 2025-04-14T00:00:00Z | 1 | NA |
| delivery-2 | 2025-04-14T01:00:00Z | 1 | NA |
| delivery-3 | 2025-04-15T02:00:00Z | 1 | RM |
| delivery-4 | 2025-04-15T00:00:00Z | 2 | MI |
Parallelamente, su un’altra base dati, è presente una tabella che tiene traccia della capacità settimanale disponibile
per ogni recapitista-provincia, insieme alla capacità già utilizzata:
| delivery_driver_id | province | capacity | used_capacity |
|---|---|---|---|
| 1 | NA | 70 | 0 |
| 1 | RM | 60 | 0 |
| 2 | MI | 80 | 0 |
Il funzionamento del batch è il seguente:
quando viene letto un record di spedizione, il job verifica se la coppia recapitista-provincia ha ancora capacità
disponibile. Se sì:
- La spedizione viene processata (nel nostro esempio, semplicemente loggata) ed eliminata dalla tabella.
- La capacità utilizzata per quella partizione viene incrementata.
Se invece la capacità è terminata, la spedizione non viene processata e rimane nella tabella per essere valutata in
un’esecuzione successiva (ad esempio, la settimana dopo).
Il seguente diagramma mostra la logica di elaborazione di una spedizione:
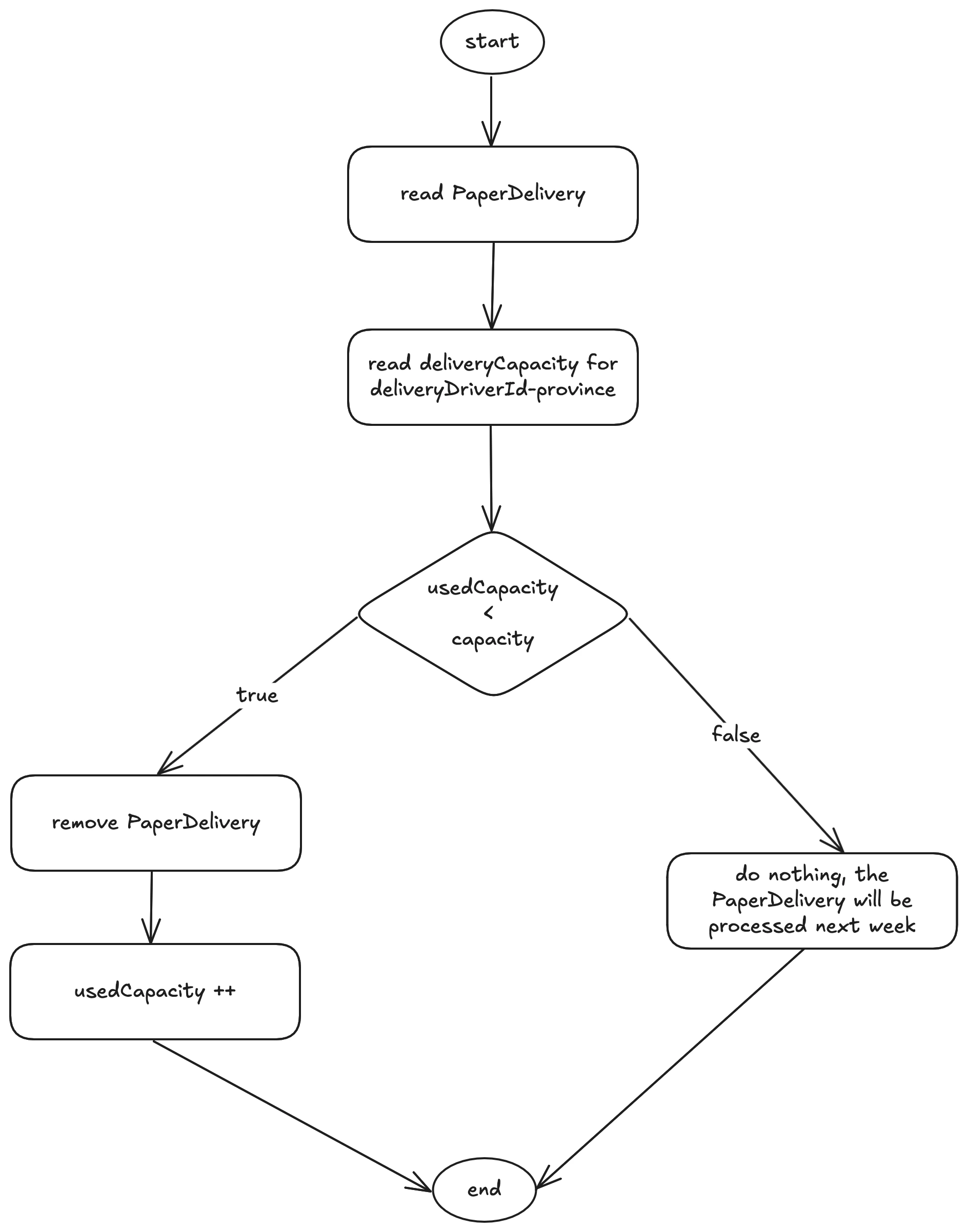
Analizzando i requisiti di business, emergono due vincoli chiave per la corretta progettazione del job:
- I record delle spedizioni facente parti della stessa partizione (
recapitista-provincia) non devono essere elaborati in parallelo, altrimenti si avrebbero problemi di concorrenza sulla valutazione della capacità. - I record di partizioni diverse possono essere elaborati in parallelo, non avendo dipendenze tra loro.
Mi sono detto quindi: "È il momento di rispolverare Spring Batch!"
Spring Batch e il partizionamento
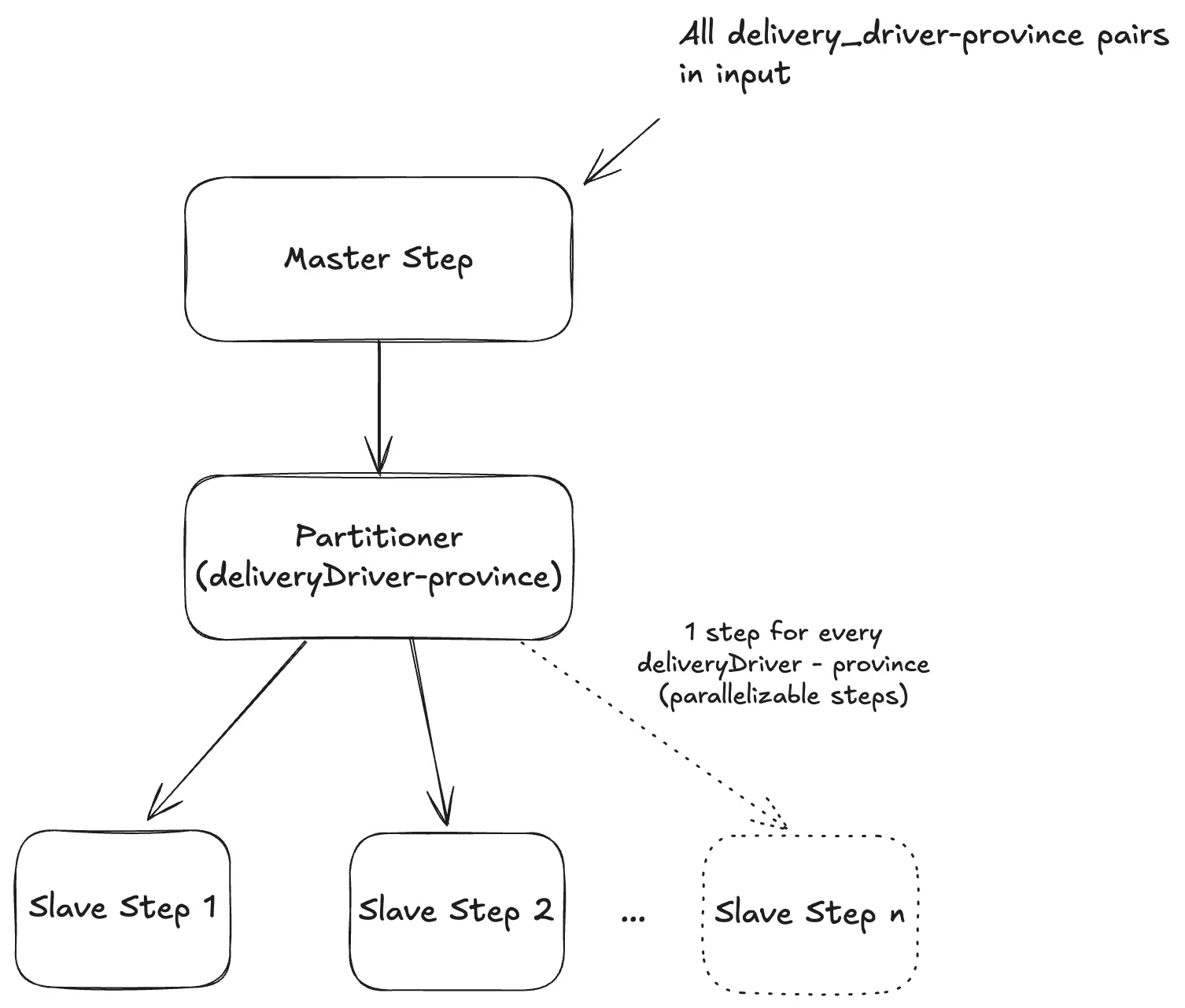
Con Spring Batch è possibile creare un Master Step che ha il solo compito di dividere il lavoro in più partizioni, assegnando ciascuna a uno Slave Step eseguito in parallelo.
Nel dettaglio:
- Un
Partitionercalcola le partizioni (nel nostro caso: le chiavideliveryDriverId##province). - Ogni partizione viene passata a uno Slave Step, che riceve i parametri tramite
ExecutionContext. - Gli step vengono eseguiti in parallelo tramite un
TaskExecutor. - In ogni Slave Step definiamo:
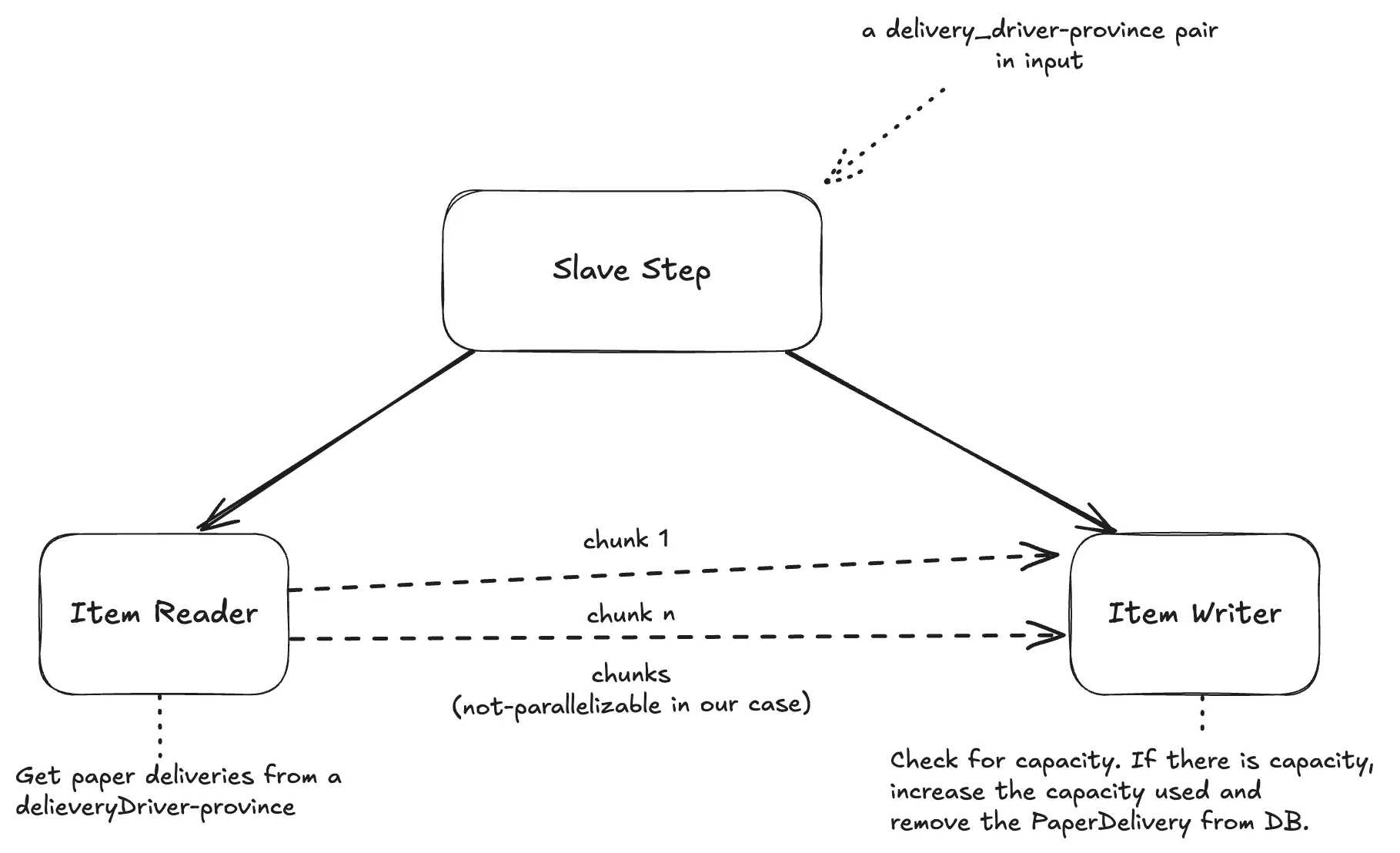
- un
ItemReaderche legge da DynamoDB usando lapk - un
ItemWriterche processa i record sequenzialmente (chunk-based)
- un
Di seguito viene mostrato un diagramma del funzionamento del Master Step:
Di seguito viene mostrato anche un diagramma del funzionamento dello Slave Step:
Prerequisiti
- Java 21 o superiori.
- Installazione di Podman o Docker nella macchina per eseguire il container di LocalStack, che permette di utilizzare DynamoDB in locale.
L'applicazione Spring Batch
Puoi trovare tutto il codice sorgente dell'applicazione sul mio repository GitHub.
L'applicazione utilizza Java 21 e Spring Boot 3 con Spring Batch. Possiamo creare lo scheletro del progetto eseguendo la seguente cURL:
curl https://start.spring.io/starter.zip -d groupId=com.vincenzoracca \
-d artifactId=spring-batch-partitioner \
-d name=spring-batch-partitioner \
-d packageName=com.vincenzoracca.springbatchpartitioner \
-d dependencies=batch,actuator,web,distributed-tracing,lombok,postgresql \
-d javaVersion=21 -d bootVersion=3.4.4 -d type=maven-project -o spring-batch-partitioner.zip
Utilizziamo anche le dipendenze di Spring MVC (Web), Spring Boot Actuator e Micrometer Tracing (Distributed Tracing) in modo
tale da poter monitorare l'esecuzione del batch aggiungere il traceId e lo spanId ai log del Job. Tutti gli Slave Step
appartenenti allo stesso Master Step avranno lo stesso TraceID ma diverso SpanID.
Aggiungiamo poi la dipendenza JDBC di Postgres in quanto utilizziamo questo database per memorizzare i metadati
delle esecuzioni dei Job di Spring Batch.
Inoltre centralizziamo le versioni delle dipendenze di Spring Cloud AWS (che si servono per utilizzare DynamoDB),
aggiungendo questo pezzo di codice al pom.xml:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.awspring.cloud</groupId>
<artifactId>spring-cloud-aws-dependencies</artifactId>
<version>3.3.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Infine, aggiungiamo la dipendenza di Spring Cloud AWS per DyanamoDB:
<dependency>
<groupId>io.awspring.cloud</groupId>
<artifactId>spring-cloud-aws-starter-dynamodb</artifactId>
</dependency>
Step 1: creazione delle entità
Creiamo il package middleware.db.entity e scriviamo le classi che rappresentano le entità descritte a inizio articolo:
// DeliveryDriverCapacity.java
@DynamoDbBean
@Data
public class DeliveryDriverCapacity {
private String pk; // deliveryDriverId##province
private String deliveryDriverId;
private String province;
private long capacity;
private long usedCapacity;
@DynamoDbPartitionKey
public String getPk() {
return pk;
}
}
// PaperDelivery.java
@DynamoDbBean
@Data
public class PaperDelivery {
private String pk; // deliveryDriverId##province
private Instant createdAt;
private String deliveryDriverId;
private String province;
private String requestId;
@DynamoDbPartitionKey
public String getPk() {
return pk;
}
@DynamoDbSortKey
public Instant getCreatedAt() {
return createdAt;
}
}
Step 2: creazione del job runner
Scriviamo la classe che fa partire il batch. Creiamo il package job.runner con la seguente classe:
@Component
@RequiredArgsConstructor
public class PaperDeliveryJobRunner {
private final Job job;
private final JobLauncher jobLauncher;
@Scheduled(cron = "${paper-delivery-cron}")
public void run() throws Exception {
var pks = ExternalService.buildPks();
JobParameters jobParameters = new JobParametersBuilder()
.addJobParameter("pks", pks, String.class)
.addJobParameter("createAt", Instant.now().toString(), String.class)
.toJobParameters();
jobLauncher.run(job, jobParameters);
}
}
Il metodo run viene eseguito più volte secondo una cron expression, contenuta nella annotazione @Scheduled.
Questo metodo, invoca un servizio esterno che restituisce una stringa contenente tutte le coppie
deliveryDriverId-province, nel seguente formato: delivery-driver-1##province1,deliveryd-river-2##province2....
Una volte recuperata questa stringa, questa viene passata come parametro del Job. Infine, il job viene avviato.
Step 3: creazione del partitioner utilizzato dal Master Step
Creiamo la classe partitioner utilizzata dal Master Step, che prende in input tutte le chiavi nel formato deliveryDriverId##province
e per ogni chiave crea una partizione.
public class PaperDeliveryPartitioner implements Partitioner {
private final List<String> pks;
public PaperDeliveryPartitioner(List<String> pks) {
this.pks = pks;
}
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> partitions = HashMap.newHashMap(pks.size());
for (int i = 0; i < pks.size(); i++) {
ExecutionContext context = new ExecutionContext();
context.putString("pk", pks.get(i));
partitions.put("partition" + i, context);
}
return partitions;
}
}
Il parametro gridSize è uguale alla dimensione della lista pks, per cui possiamo usare lui o pks.size() indifferentemente.
Step 4: creazione dell'item reader utilizzato dallo Slave Step
Creiamo il package job.reader e scriviamo la classe ItemReader, che dato in input un pk (cioè una stringa
deliveryDriverId##province), recuperi da DynamoDB tutte le spedizioni associate a quella coppia:
@RequiredArgsConstructor
@Slf4j
public class PaperDeliveryReader implements ItemReader<PaperDelivery>, StepExecutionListener {
private final DynamoDbTemplate dynamoDbTemplate;
private Iterator<PaperDelivery> iterator;
@Override
public void beforeStep(StepExecution stepExecution) {
ExecutionContext context = stepExecution.getExecutionContext();
var pk = context.getString("pk");
this.iterator = loadData(pk).iterator();
log.info("Reading paper deliveries with pk {}", pk);
}
private List<PaperDelivery> loadData(String pk) {
QueryEnhancedRequest query = QueryEnhancedRequest.builder()
.queryConditional(QueryConditional.keyEqualTo(k -> k.partitionValue(pk))).build();
PageIterable<PaperDelivery> pageIterable = dynamoDbTemplate.query(query, PaperDelivery.class);
return StreamSupport.stream(pageIterable.items().spliterator(), false).toList();
}
@Override
public PaperDelivery read() {
return (iterator != null && iterator.hasNext()) ? iterator.next() : null;
}
}
Step 5: creazione dell'item writer utilizzato dallo Slave Step
L'ItemWriter prende le spedizioni associata ad una stessa partizione deliveryDriverId##province ed effettua
la logica sulla capacità. Creiamo il package job.writer e scriviamo la seguente classe:
@Slf4j
@RequiredArgsConstructor
public class LogWriter implements ItemWriter<PaperDelivery> {
private final DynamoDbTemplate dynamoDbTemplate;
@Override
public void write(Chunk<? extends PaperDelivery> chunk) {
String pk = chunk.getItems().get(0).getPk();
DeliveryDriverCapacity deliveryDriverCapacity = dynamoDbTemplate.load(Key.builder()
.partitionValue(pk)
.build(), DeliveryDriverCapacity.class);
chunk.forEach(paper -> {
if (deliveryDriverCapacity != null &&
deliveryDriverCapacity.getUsedCapacity() < deliveryDriverCapacity.getCapacity()) {
deliveryDriverCapacity.setUsedCapacity(deliveryDriverCapacity.getUsedCapacity() + 1);
log.info("Paper Delivery DONE: {}",paper);
dynamoDbTemplate.delete(paper);
} else {
log.warn("PaperDelivery DISCARDED because there is no delivery driver capacity: {}, {}",
paper.getRequestId(), paper.getPk());
}
});
dynamoDbTemplate.save(deliveryDriverCapacity);
}
}
Nota che il metodo write prende come parametro un Chuck delle spedizioni. Questo significa che possiamo decidere
di dividere in più chuck le spedizioni di una stessa partizione, in modo tale da alleggerire l'elaborazione. Tuttavia, per
il nostro caso d'suo, è importante che i chuck non vengano eseguiti in parallelo, per evitare problemi di inconsistenza
sulla valutazione della capacità.
Step 6: creazione del job completo
Infine, scriviamo il job completo, formato da due step, Master Step e Slave Step. Creiamo il package job.config e scriviamo la seguente classe:
@Configuration
@EnableBatchProcessing
@Slf4j
@RequiredArgsConstructor
public class PaperDeliveryJobConfig {
private final DynamoDbTemplate dynamoDbTemplate;
private final PlatformTransactionManager transactionManager;
private final JobRepository jobRepository;
// Used to run Slave Steps in parallel
private TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setQueueCapacity(10);
executor.setThreadNamePrefix("part-thread-");
executor.initialize();
return executor;
}
@Bean
@StepScope
public PaperDeliveryReader reader() {
return new PaperDeliveryReader(dynamoDbTemplate);
}
@Bean
public ItemWriter<PaperDelivery> writer() {
return new LogWriter(dynamoDbTemplate);
}
@Bean
public Step slaveStep() {
return new StepBuilder("slaveStep", jobRepository)
.<PaperDelivery, PaperDelivery>chunk(10, transactionManager)
.reader(reader())
.writer(writer())
.build();
}
@Bean
@JobScope
public Step masterStep(@Value("#{jobParameters[pks]}") String pkParam) {
List<String> pks = Arrays.asList(pkParam.split(","));
return new StepBuilder("masterStep", jobRepository)
.partitioner("slaveStep", new PaperDeliveryPartitioner(pks))
.step(slaveStep())
.taskExecutor(taskExecutor())
.gridSize(pks.size())
.build();
}
@Bean
public Job paperDeliveryJob(Step masterStep) {
return new JobBuilder("paperDeliveryJob", jobRepository)
.start(masterStep)
.build();
}
}
In questa classe è rilevante la configurazione del Master Step. Questo prende in input il job parameter
pks passato dal runner, lo splitta per ricavare le varie coppie deliveryDriverId##province e infine le passa al
partitioner. Qui puoi vedere chiaramente che il gridSize viene settato col valore pks.size(). Inoltre, a questo step
viene assegnato un taskExecutor per parallelizzare l'esecuzione degli Step Slave.
Step 7: inizializziamo il database
Allo startup dell'applicazione, inseriamo 2 spedizioni per ogni coppia deliveryDriverId##province. Inoltre, inizializziamo
tutte le capacità a 2, tranne per le coppie 1##RM e 2##NA, che hanno capacità 1. In questo modo, per queste coppie
possiamo simulare il caso di capacità terminata:
@SpringBootApplication
@EnableScheduling
@Slf4j
public class SpringBatchAwsApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBatchAwsApplication.class, args);
}
@Bean
CommandLineRunner commandLineRunner(DynamoDbTemplate dynamoDbTemplate) {
return args -> {
cleanDb(dynamoDbTemplate, PaperDelivery.class);
cleanDb(dynamoDbTemplate, DeliveryDriverCapacity.class);
String[] pks = ExternalService.buildPks().split(",");
int numberOfRequest = 2;
log.info("Initialization {} requestId for every {} pair deliveryDriverId##Province", numberOfRequest, pks.length);
Stream.of(pks).parallel().forEach(pk -> {
String[] deliveryDriverProvince = pk.split("##");
var deliveryDriverId = deliveryDriverProvince[0];
var province = deliveryDriverProvince[1];
DeliveryDriverCapacity deliveryDriverCapacity = buildDeliveryDriverCapacity(pk, deliveryDriverId, province);
dynamoDbTemplate.save(deliveryDriverCapacity);
for(int i = 0; i < numberOfRequest; i++) {
PaperDelivery paperDelivery = buildPaperDelivery(pk, deliveryDriverId, province);
dynamoDbTemplate.save(paperDelivery);
}
});
};
}
private static PaperDelivery buildPaperDelivery(String pk, String deliveryDriverId, String province) {
PaperDelivery paperDelivery = new PaperDelivery();
paperDelivery.setPk(pk);
paperDelivery.setCreatedAt(Instant.now());
paperDelivery.setRequestId(UUID.randomUUID().toString());
paperDelivery.setDeliveryDriverId(deliveryDriverId);
paperDelivery.setProvince(province);
return paperDelivery;
}
private static DeliveryDriverCapacity buildDeliveryDriverCapacity(String pk, String deliveryDriverId, String province) {
DeliveryDriverCapacity deliveryDriverCapacity = new DeliveryDriverCapacity();
deliveryDriverCapacity.setPk(pk);
deliveryDriverCapacity.setDeliveryDriverId(deliveryDriverId);
deliveryDriverCapacity.setProvince(province);
if(pk.equals("1##RM") || pk.equals("2##NA")) {
deliveryDriverCapacity.setCapacity(1L);
}
else {
deliveryDriverCapacity.setCapacity(2L);
}
deliveryDriverCapacity.setUsedCapacity(0L);
return deliveryDriverCapacity;
}
private <T> void cleanDb(DynamoDbTemplate dynamoDbTemplate, Class<T> clazz) {
PageIterable<T> pages = dynamoDbTemplate.scanAll(clazz);
StreamSupport.stream(pages.items().spliterator(), false)
.forEach(dynamoDbTemplate::delete);
}
}
Step 8: avviamo l'applicazione
Nel progetto troverai un file compose.yml che permette di eseguire Postgres e DynamoDB in locale. Accertati che Docker o Podman siano avviati, dopodichè apri un terminale dalla root del progetto ed esegui il comando:
docker compose up -d # Docker
e poi:
./mvnw clean spring-boot:run
Il job partità al secondo 0 di ogni minuto, poiché nel file application.properties abbiamo:
paper-delivery-cron=0 */1 * * * *
Analizzando i log, vedremo che gli Slave step partiranno in parallelo. Inoltre, tutte le spedizioni di uno stesso Step Slave, cioè, di una stessa partizione, avranno lo stesso thread, lo stesso TraceID e lo stesso SpanID:
[ part-thread-4] [67fbd9a4bc4011ed462226cf7d5187fb-462226cf7d5187fb]...:
Reading paper deliveries with pk 2##NA
[ part-thread-4] [67fbd9a4bc4011ed462226cf7d5187fb-462226cf7d5187fb]...:
Paper Delivery DONE: PaperDelivery(pk=2##NA, createdAt=2025-04-13T15:34:45.630071Z, deliveryDriverId=2, province=NA, requestId=8779789a-7e5e-4c84-ad33-4a152d0c4e4c)
[ part-thread-4] [67fbd9a4bc4011ed462226cf7d5187fb-462226cf7d5187fb]...:
PaperDelivery DISCARDED because there is no delivery driver capacity: 1e188367-4800-4144-86a6-a2477cc4c4fc, 2##NA
Conclusioni
In questo articolo abbiamo visto come risolvere un problema comune, cioè quello di creare batch con un esecuzione partizionata. Utilizzando Spring Batch, è possibile creare un Master Step che abbia la responsabilità di partizionare ed eseguire Slave Step, in modo molto semplice e parallelizzabile.
Altri articoli su Spring: Spring.
Se vuoi creare API sicure e scalabili con Spring Boot, acquista il mio libro Spring Boot 3 API Mastery su Amazon!
Altri libri consigliati su Spring, Docker e Kubernetes:
- Cloud Native Spring in Action: https://amzn.to/3xZFg1S
- Pro Spring 6: An In-Depth Guide to the Spring Framework: https://amzn.to/4g8VPff
- Pro Spring Boot 3: An Authoritative Guide With Best Practices: https://amzn.to/4hxdjDp
- Docker: Sviluppare e rilasciare software tramite container: https://amzn.to/3AZEGDI
- Kubernetes. Guida per gestire e orchestrare i container: https://amzn.to/3EdA94v